Building a spatial querying and data manipulation engine
Introduction
Spatial computing and emergence of massive scale spatial data is becoming increasingly important with the proliferation of mobile devices, cost effective and ubiquitous positioning technologies, development of high resolution imaging technologies, and contribution from a large number of community users. With startups like Uber, Instacart, Grubhub generating, ingesting, storing and processing massive amounts of spatial data, leading the spatial data revolution. However, the needs of storing and processing large-scale spatial data are poorly met by current general-purpose storage systems and calls for a more efficient spatio-temporal data management system.
In this blog-post, we’ll talk about the do’s and don’ts of location data management and explore possible ways of storing and retrieving OpenStreetMap (OSM) data into the big-data ecosystem.
Basic requirements
- Ease of use, versatile - easy querying and retrieving data as Spark dataframes, with robust APIs for Scala, Python and SparkSQL
- Cost effective - avoid storage of data in RDS or in-memory due to exorbitant cost of keeping the instance up all the time. Disk-based storage (AWS S3) or cold storage (AWS Glacier) preferred
- Fault tolerant - continue to operate even in the presence of node failures. Avoid single-node RDS monoliths.
- Fast, interactive querying - ability to run interactive analytic queries with compute being horizontally scalable, rather than vertical.
Query support
- kNN queries- takes a set of points R, a query point q, and an integer k ≥ 1 as input, and finds the k nearest points in R to q
- Range queries - takes range R and a set of geometric objects S, and returns all objects in S that lie in the range R
- Spatial joins - takes two input sets of spatial records R and S and a join predicate θ (e.g., overlap, intersect, contains, etc..)
- Distance joins - special case of spatial join where the join predicate is withindistance
Example use-cases
- Traffic analysis - hourly speed profile of the entire city, with a formula of distance/time between successive pings, uses st_distanceSpheroid
- Map matching - snaps driver’s noisy GPS coordinates to the underlying road network using stochastic state space models, uses st_distance
- Polygon coverage - find number of trips originating from a polygon over total number of trips, uses st_contains
- Address distribution - find the number of customer addresses within x meters of each other, uses st_distanceSphere
Pictorically,
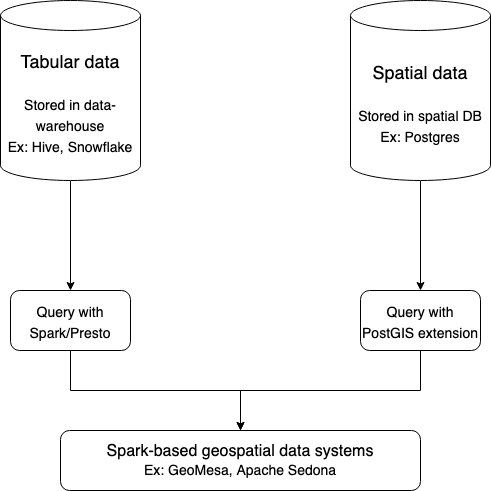
Figure 1: Representation of data warehouses and querying engines
Why not x?
Geospatial querying can be accomplished by PostgreSQL with PostGIS extension, Spatial Hadoop, LocationSpark and GeoMesa.
Why not PostgreSQL + PostGIS?
- PostgreSQL as a datastore is not horizontally scalable, only vertically scalable. This can cause potential bottlenecks when terabytes of data is stored and analysed.
- The Spark-JDBC connector used to convert PostgreSQL results back to Spark dataframe implements query-pushdown. At large-scale, this design makes PostgreSQL I/O bound rather than compute-bound.
- Fails to leverage the power of distributed memory and cost-effectiveness of big-data.
- Susceptible to failures, since this is a single node, vertically scalable RDS monolith
Full performance comparison is published at VLDB 2013, as part of Hadoop-GIS: A High Performance Spatial Data Warehousing System over MapReduce benchmarks.
Why not Hadoop-GIS or Spatial Hadoop?
Hadoop-GIS is unable to reuse intermediate data and writes intermediate results back to HDFS. (not just Hadoop-GIS, but Hadoop in general).
Why not LocationSpark, GeoSpark (Apache Sedona), Magellan, SpatialSpark?
To address the challenges faced by Hadoop, in-memory cluster computing frameworks for processing large-scale spatial data were developed based on Spark.
- Apache Sedona - still in incubation and active development, no kNN joins
- LocationSpark - limited data types, no recent development
- Magellan - high shuffle costs, no range query optimizations
- SpatialSpark - high memory costs, no recent development
For a detailed analysis, please refer to How Good Are Modern Spatial Analytics Systems? - VLDB ‘18
Why GeoMesa?
GeoMesa provides a suite of tools to manage and analyze huge spatio-temporal datasets and is a full-fledged platform.
- Provides support for near real time stream processing of spatio-temporal data by layering on top of Apache Kafka
- Supports a host of data-stores like Cassandra, Bigtable, Redis, FileSystem (S3, HDFS), Kafka and Accumulo.
- Supports Spark Analytics, with robust APIs for Scala-spark, SparkSQL and PySpark - can be used only for distributed querying and analytical needs.
- Horizontally scalable (add more nodes to add more capacity)
- Provides JSON, Parquet, Shapefile converters for ingesting data into GeoMesa
- Mature and under active development, with community support (7 years old, latest 3.1.0 release on 28th October, 2020)
Conclusion
GeoMesa seems a clear winner and checks all the requirements for a fully-stable, cost-effective, fault tolerant, large-scale geospatial analytics platform.
Some advice on how to set-up :
- Choose AWS S3, Hadoop HDFS, Google FileStorage or Azure BlobStore as the datastore, depending on the rest of your environment
- Partition the data into folders, by date, by city or by country, depending on your scale and use-case
- Create a cron job to download OSM data from here (to avoid staleness, say weekly)
- Ingest and convert data obtained from #3 into GeoMesa format, index and store it
- Use the FileSystem RDD Provider inside GeoMesa Spark and run any spark based spatial workloads!
References
- [Code] GeoMesa - NYC Taxis, GeoMesa + H3 Notebook
- [Paper] Hadoop-GIS: A High Performance Spatial Data Warehousing System over MapReduce
- [Book] An Architecture for Fast and General Data Processing on Large Clusters - M. Zaharia - ACM ‘16
- [Benchmark] Benchmarking of Big Data Technologies for Ingesting and Querying Geospatial Datasets
- [Benchmark] How Good Are Modern Spatial Analytics Systems?
- [Github] locationtech/geomesa, apache/incubator-sedona