Multi-headed models in Tensorflow
Introduction
In a typical machine learning lifecycle, DS deploys machine learning models which have close resemblance to each other. These models when deployed in production generate individual APIs for clients to integrate. This approach makes sense if the models are sequential, i.e output of one is passed as input to another, but not for models which are all called at once and are independent of each other. In cases like these, it is suboptimal for clients to integrate with “x” number of APIs. A classic example for this is when you not only want to classify the image, but also want to localize the object and find coordinates of the bounding box around it.
Why multi-headed models?
- Reduces the number of calls to DSP, saving network cost and reducing overall latencies.
- Piggybacks on feature fetches, reducing the resources for inferencing and saving inference cost. (feature fetch happens once rather than “x” times)
What are multi-headed models?
Every DL model is made up of two components, the backbone network and the head. The backbone is everything except the loss calculation, optimization and evaluation metrics. You can either have multiple heads for a single backbone or multiple heads for multiple backbones.
An example for the former approach is classification with localizalization. If you were to classify the image but also want to localize the object (find the bounding box coordinates around it), you would have a classification head as well as a regression head.
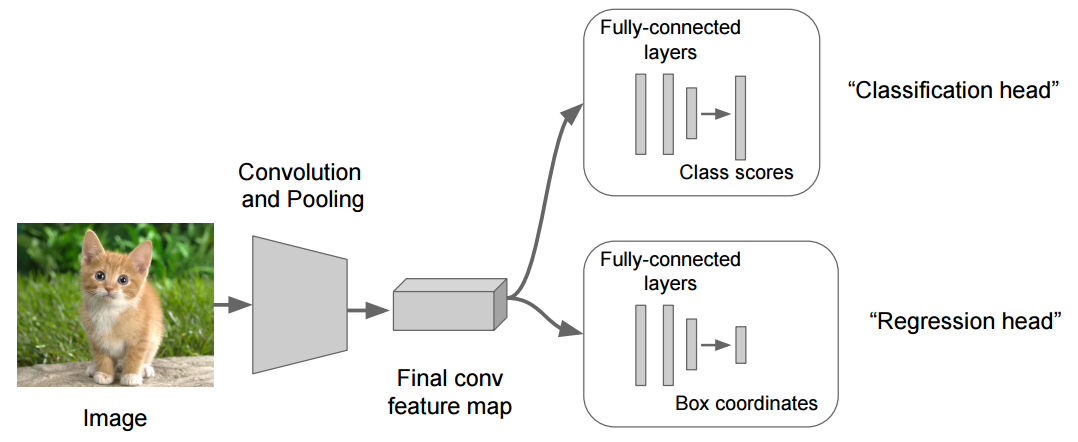
An example for the latter approach is used in DL mdoels. Input features are the same across all the models, but the backbone and the heads are different for each model.
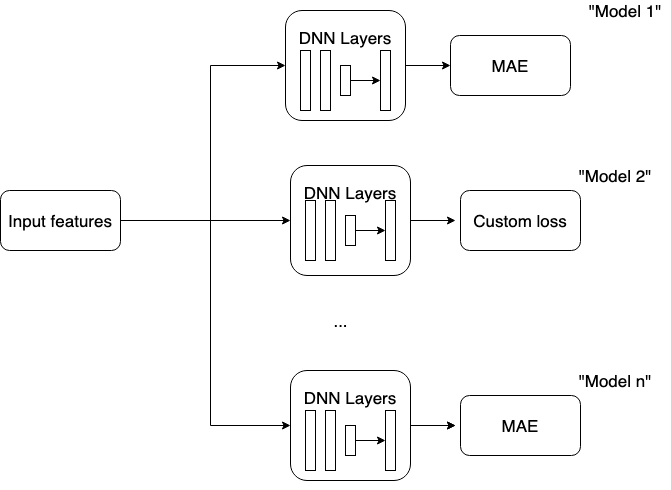
Constraint : Input data should remain the same across all the models. Input features can change (to create the input layer), but no filtering across rows is possible. TLDR: Data filtering possible across columns, but not across rows.
How to implement it?
There are two ways of accomplishing multi-headed models in Tensorflow -
Summing before minimization
final_loss = tf.reduce_mean(loss1 + loss2)
train_op = tf.train.AdamOptimizer().minimize(final_loss)
Jointly minimizes the combined loss and calculates gradient on the sum.
Disjoint training
train_op1 = tf.train.AdamOptimizer().minimize(loss1)
train_op2 = tf.train.AdamOptimizer().minimize(loss2)
final_train_op = tf.group(train_op1, train_op2)
Keeps separate gradient accumulators for each loss. tf.group guarantees when the final_train_op is finished, both the operations train_op1 and train_op2 should have finished. This creates separate optimizers leading to different backpropagation graphs (within the same tf.Graph), independent loss functions and independent gradient accumulators.
Advantages of #2 over #1
- No cannibalization takes place when losses are of different magnitudes. Say if modelA has loss = 100, modelB has loss = 0.5, in case of #1, the overall model will start penalizing modelA more and neglect modelB. In case of #2, since accumulators are different, cannibalization effect doesn’t happen.
- In case of multi-task learning, #2 allows you to define different learning rates to models, thereby “intentionally” giving more importance to one task over the other (task weights)
References
- [Github issue] How to define multiple loss function and train_op in tf.estimator.EstimatorSpec · Issue #15773 · tensorflow/tensorflow. Refer to the comments by @ispirmustafa who’s the creator of Tensorflow Estimators.
- [StackOverflow] What is a multi-headed model? And what exactly is a ‘head’ in a model?
- [Paper] [1708.02637] TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks