groupByKey vs reduceByKey in spark
- Introduction
- Latency
- RDDs
- Partitioning
- Shuffling
- groupByKey
- reduceByKey
- Even faster reduceByKey
- Takeaway
- References
Introduction
Spark is a fast and general purpose cluster computing system hosted by Apache foundation. It provides general purpose distributed computing framework and high level APIs for Scala, Python and R. This post assumes working understanding of Spark internals like worker nodes, driver node, executors, cluster manager, RDDs, and the likes.
Latency
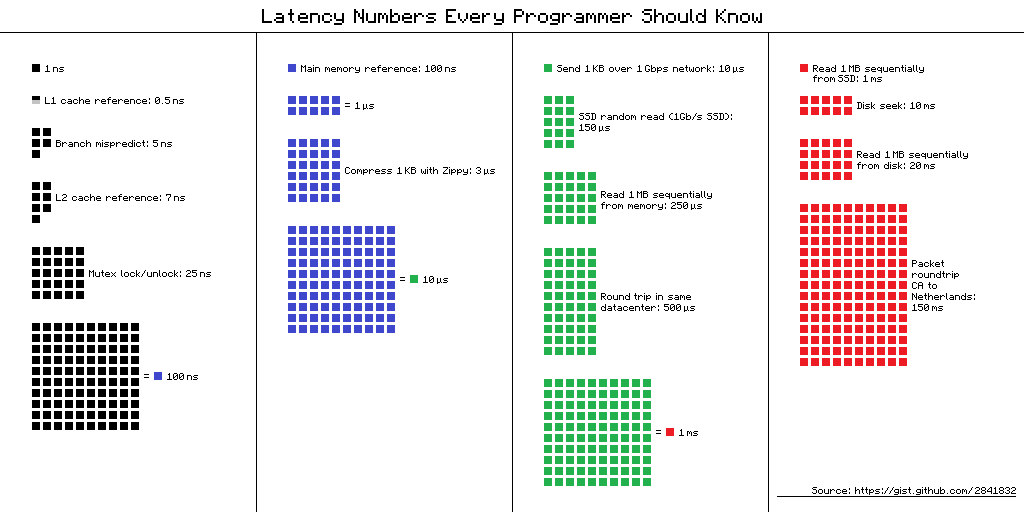
From the above diagram,
cache » memory (RAM) » network » disk.
Spark triumphed over hadoop since hadoop used to write output of intermediate operations to disk, and read/write from disk for each operation. As seen, the latency was huge in case of hadoop. Spark was a bump over hadoop where all intermediate outputs were written to memory and read from memory.
Resilient Distributed Datasets
The main data storage unit of spark are RDDs. These store memory references to partitions of data stored on different nodes across a cluster. It contains two types of operations: transformations and actions. Transformations are lazy evaluation and actions are eager execution.
Partitioning
Data when stored in RDDs is split across nodes of the cluster. The decision of which key-value pair goes to which node is decided by the partitioning logic. Each partitioning algorithm has its advantages and disadvantages.
- Hash partitioning - Pass the key to a hash function to determine the node number to which the key will be passed to. This method attemps to spread data evenly across partitions.
val n = k.hashCode() % numNodes - Range partitioning - Therotically, define boundaries given a partition range to achieve uniform distribution across nodes. Practically, sample a small subset of keys to generate boundaries. Tuples with keys in the same range appear on the same machine.
Some transformations like map, flatMap don’t inherit parent partition function (as the keys might have changed). Some other transformations like mapValues inherit parent partition function because it operates on the value only.
Shuffling
Co-location significantly increases the performance of data-intensive applications. Shuffling helps achieve co-location, by moving grouped keys from one partition to another. While shuffling, spark uses partitioning to determine which key-value pair should be sent to which machine. Shuffle potentially creates data-skew where one partition contains a lot of data and the other doesn’t, leading to increased wait-times. This helps identifying the problem, this helps solving the problem partially by creating dummy keys
groupByKey
This method brings all the keys belonging to the same group on one of the executor nodes by partitioning the hash value and pulling the result into memory to group as iterators. Each record whose key has the same hash value must live in memory on a single machine (co-location). In the word-count example, groupByKey results in same words shuffled to single partition. There’s no parallelism here and is strictly a sequential operation.
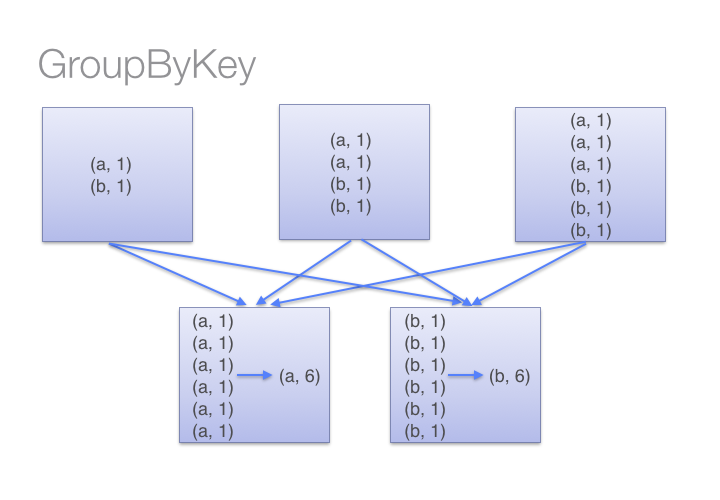
Disadvantages:
- If just one of the keys contains too many records to fit in memory on one executor, the entire operation will fail and result in out-of-memory error (OOM)
- Co-location is nice to have, but is expensive.
reduceByKey
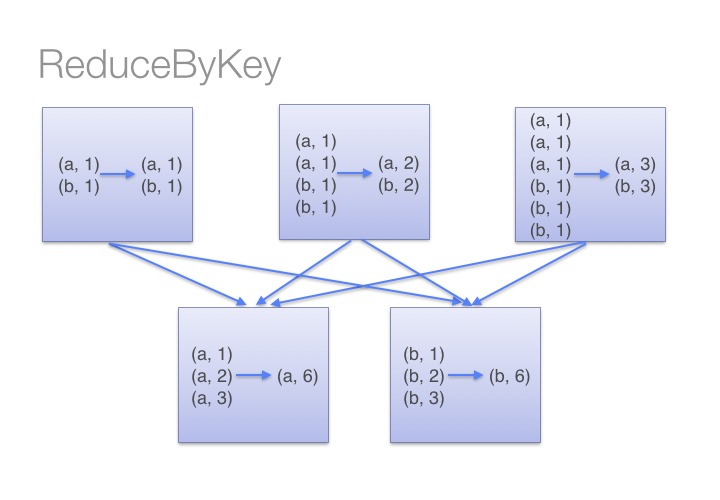
In case of associative operations like sum, max, there’s a faster way to achieve the result. Using the parallelism provided by spark, reduceByKey performs these reductions locally first (on executors), and then once again on the driver saving a ton of network traffic. In spark world, its also called “map-side reduce”
Instead of sending all the data over the network, this method reduces it as small as it can and then send reductions over the wire. It can be distributed since each partition can be executed independent of the other partitions.
Taking a look at the source code, reduceByKey is a specialization of combineByKey where, mergeValues and mergeCombiners are the same function.
Even faster reduceByKey
Using reduceByKey instead of groupByKey localizes data better due to different partitioning strategies and thus reduces latency to deliver performance gains. We can improve the performance of reduceByKey even further by avoiding shuffling altogether. To achieve this, data has to be manually repartitioned using partitionBy. Efficient partitions can be created when keys belonging to the same group colocate on the same partition.
events = sc.textFile('events.txt')
partitioner = RangePartitioner(8, events)
eventsP = events.partitionBy(partitioner).persist()
eventsP.reduceByKey(add)
This gives 9 times speed-ups in practical tests.
Takeaway
- The way data is organized on the cluster and the actions define latency of spark applications. in practical scenarios, you should spend considerable time finding optimal way of partitioning the data across nodes.
- Co-location can improve performance, but is hard to guarantee.
- Shuffling is data-intensive operation. Use it cautiously.
References
- https://learning.oreilly.com/library/view/High+Performance+Spark/9781491943199/ch06.html#group_by_key
- https://learning.oreilly.com/library/view/learning-spark/9781449359034/ch04.html
- https://databricks.gitbooks.io/databricks-spark-knowledge-base/best_practices/prefer_reducebykey_over_groupbykey.html