Word vectors
- Words
- Representation
- Word2vec
- Probability model
- Objective function
- Gradient descent
- Practical difficulties
- Subsampling
- References
Words
“meaning” is the idea that a person wants to express by using words, signs, etc. Every conversation between two humans comprise a bunch of words, which are used to convey meaning. But plain strings don’t contain much information by themselves, and are of negligable use for the computer. There has to be a representation which converts words to a set of integers, understandable by computers.
Representation
The first and arguably most important common denominator across all NLP tasks is how we represent words as input to any of our models. Early NLP works treat words as atomic symbols. Recent works treat words as to contain some notion of similarity and difference between words
Bag of words
This approach considers each word as a seperate entity where the order doesn’t matter. One example of bag of words approach was one-hot encoders which had one vector for each word. 1s occured where the word occured, 0s occured where the word didn’t occur.
Disadvantages:
- Huge vocabulary - infinite space of words. As and when the model sees new words, it adds additional 0 to the 2-D matrix. The 2-D matrix formed is in the form of word * exists
- No natural notion of similarity - two words which are similar have orthogonal vectors.
Distributional semantics
In order to combat the disadvatages of above approach, distributional sematic approach was introduced, where the word’s meaning is given by words that appear close-by. Some models of this approach are word2vec, GLoVE.
Word2vec
This approach belongs to a class of algorithms known as predictor-corrector or iterative-update algorithms. It conserves the sequence of words (as opposed to bag of words). There exist two variants of word2vec depending on the input and output. CBoW (continuous bag of words) and skip-gram.
Working of the model:
- To start off with, we initialize all vectors randomly
- Objective is given the center word c, predict the outside word o : skipgram model.
- To find the closeness between two words, finding cosine similarity or dot product should suffice. In ideal cases, dot product between \(W_o\) and \(W_c\) should be 1, since o and c are next to each other. In real world scenarios, dot product isn’t exactly 1, resulting in delta. Given this delta, we backpropagate and push the word vectors towards one another.
Probability model
Joint probability represented by the product of probability of outer words o in the window m given center word c.
\[L(\theta)=\prod_{t=1}^{T} \prod_{-m \leq j \leq m \atop j \neq 0} P\left(w_{t+j} | w_{t} ; \theta\right)\]where,
\[P(o | c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w}^{T} v_{c}\right)}\]Dissecting the above equation, dot product signifies how close two words are towards each other. If two words are exactly the same, dot product is 1. If two words are not at all correlated, dot product is -1.
Numerator signifies the relative closeness of outer word with respect to center word. Denominator signifies the relative closeness of all words in the dictionary with respect to center word. This equation resembles softmax where we normalize the closeness on a scale from 0 to 1, to give a probability distribution over entire vocabulary. Exponentiation is used to eradicate possible negetive sign arising from the dot product
Objective function
The ultimate objective of the loss function is to minimize negetive log likelihood. Minimizing negetive log likelihood indirectly means maximizing log likelihood.
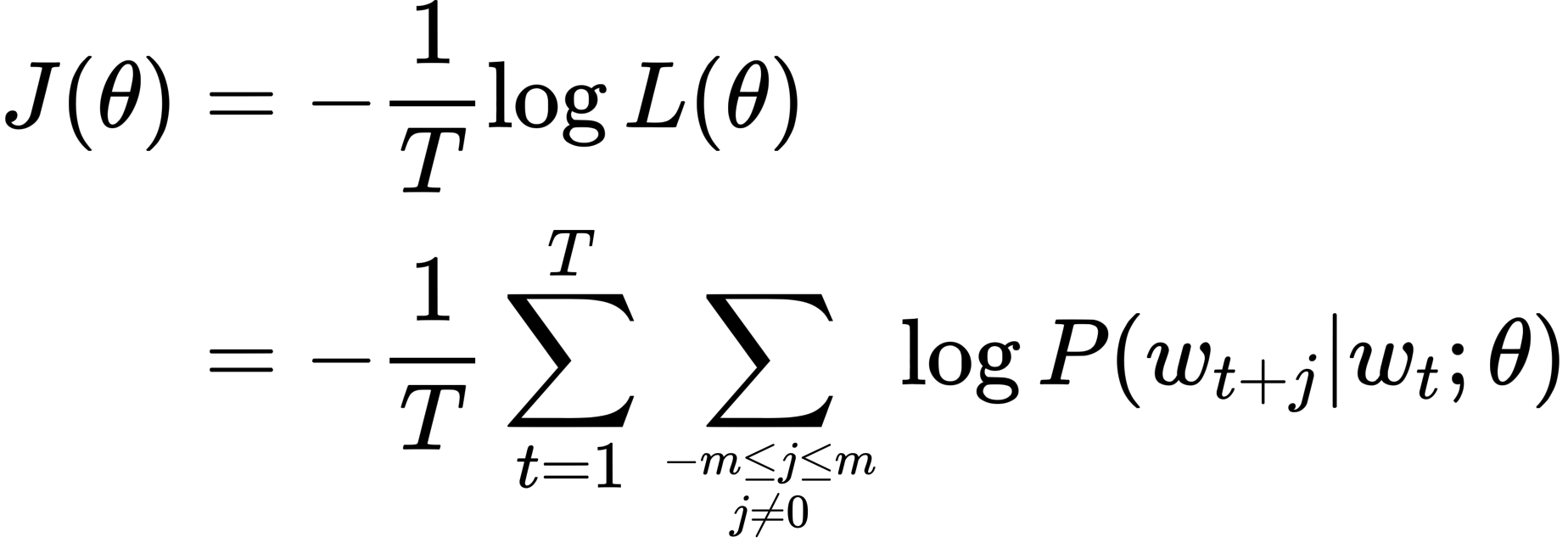
Why not maximize positive likelihood?
Convex functions shoot up at either ends and have a slope (derivative) of 0 at the center of the curve. Research suggests that it is easy to reach this point using efficient gradient descent. Minimization helps us find global minima in convex functions. If suppose maximization would’ve been used, it’ll shoot up on both ends of the convex function.
Other way of looking at it is, minimizing objective function is equivalent to maximizing predictive accuracy.
Why log?
Vanilla average likelihood is not normalized and can range from 0 to huge powers of 10. To keep the values consistent, logarithms are a good scale.
Gradient descent
As mentioned above, word2vec belongs to a class of algorithms known as iterative-update algorithms. Gradient descent step performs the iterative update as given by the formula below
Let’s take a precise example for \(v_c\) (vector for center word).
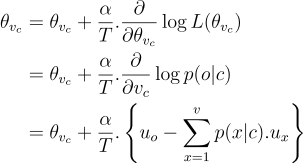
The summation term is weighted representation of each word multiplied with the probability in current model, summed over entire vocabulary. This is also called expectation. The term in curly braces signify the difference between observed representation of outer word and expected representation of what model thinks outer word should be.
Two scenarios expected:
- If expected is larger than observed, difference is negetive and the model adjusts weights such that new expected is lesser than old.
- If expected is smaller than observed, difference is positive and the model adjusts weights such that new expected is larger than old.
Why negetive gradient
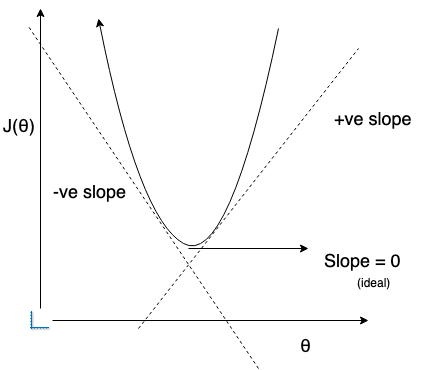
Ultimate motive of gradient descent is to bring derivate to zero, at the bottom of convex curve. This also leads the expectation to be closer to observed. There are two scenarios:
- When the derivative is positive, means the expected is larger than observed. Weight update should decrease the expected towards the center of convex curve – refer x-axis and gradient update formula
- When the derivative is negetive, means the expected is smaller than observed. Weight update should increase the expected towards the center of convex curve – refer x-axis and gradient update formula
Practical difficulties
The probability model, \(P(o | c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w}^{T} v_{c}\right)}\) is impractical since the cost of computing the denominator is proportional to the vocabulary size. This model was first proposed by the authors of word2vec, and further optimizations were designed inorder to make it computationally scalable.
Hierarchical softmax
This is computationally efficient approximation of full softmax. In full softmax, we evaluate V vocabulary words to obtain a probability distribution. Hierarchical softmax constructs a binary tree where the leaves are V words and each walk defines which words are used to compute probability distribution. This operation takes log(V) since tree traversal is O(logN).
Negetive sampling
In this case, we train a binary logistic regression where in, for a true pair (i.e, center word and outer words in context) the score is 1, where as for noise pair (i.e, center word + random word other than context words) the score is 0. The network should be able to differentiate between negetive pair and positive pair.
The cost function is \(J_{t}(\theta)=\log \sigma\left(u_{o}^{T} v_{c}\right)+\sum_{i=1}^{k} \mathbb{E}_{j \sim P(w)}\left[\log \sigma\left(-u_{j}^{T} v_{c}\right)\right]\)
In the above equation, we want to maximize the probability of outside word co-occuring with center word (1st log) and decrease the probability of random word co-occuring with center word (2nd log). We pick k samples from the probability distribution over vocabulary words.
But as seen, we can’t maximize the log probability in convex functions, but minimize the negetive log probability. Remodelled equation looks like this, \(J_{n e g-\text {sample}}\left(\boldsymbol{o}, \boldsymbol{v}_{c}, \boldsymbol{U}\right)=-\log \left(\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)-\sum_{k=1}^{K} \log \left(\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right)\)
We want to minimize the cost function J, therefore minimizing the negetive log probability (increasing the probability of outside word co-occuring with center word) and minimize the negetive log of negetive number (means decreasing the probability of random word co-occuring with center word).
The probability with which we pick random negetive pairs is: \(\mathrm{P}(w)=U(w)^{3 / 4} / Z\)
where \(U(w)\) is the unigram distribution. 3/4 power makes the less frequent words be sampled more often compared to frequent words being sampled less often. The higher the frequency of the word, the lesser the changes of it getting picked for negetive sampling.
Subsampling
Model benefits from observing the co-occurrences of “France” and“Paris”. It benefits much less from observing the frequent co-occurrences of “France” and “the”, as nearly every word co-occurs frequently within a sentence with “the”. Frequent words like the, and, etc.. carry little meaning but co-occur with many words.
To counter the imbalance between the rare and frequent words, use a simple subsampling approach where in, subsample (downsample) frequently occuring words. The probability of deleting a word is directly proportional to the frequency of the word which means the word occuring way too frequently has a high probability of getting deleted.
References
- http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes01-wordvecs1.pdf
- https://www.youtube.com/watch?v=kEMJRjEdNzM&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z&index=2
- https://stats.stackexchange.com/questions/141087/i-am-wondering-why-we-use-negative-log-likelihood-sometimes
- https://medium.com/@aerinykim/why-do-we-subtract-the-slope-a-in-gradient-descent-73c7368644fa
- http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/