Primer on Recurrent Neural Networks
- Introduction
- Background
- The Problem Space
- Inputs and Outputs
- Complete model
- Why is it hard to train long sequences
- Hierarchical RNNs
- Attention networks
- Case study
- Open problems
- References
Introduction
Recurrent neural networks have been some of the most influential innovations in the field where data is sequential. The classic and arguably most popular use case of these networks is for Natural language processing (Language modeling), and recently applied to Time-series forecasting.
Background
- The first successful experimentation of RNNs was by Yoshua Bengio, where he published a paper along with P.Simard and P.Frasconi at IEEE in 1994 titled
Learning Long-Term Dependencies with Gradient Descent is Difficult. At the same time, Hochreiter published his MSc thesis in German discovering the vanishing or exploding gradients as sequence length increased. - Many different architectures were published in late 90s like Recursive neural nets (Frasconi ‘97), Bidirectional RNNs (Schuster ‘97), LSTM (Hochreiter ‘97), Multidimensional RNNs (Graves ‘07), GRU (Cho et al ‘14)
- Fast forward 20 years, Attention mechanisms and Encoder-Decoder (Seq2Seq) networks have gained immense popularity.
The Problem Space
Sequential data usually has a variable which varies during the course of time. Specifically, machine translation is the task of translating sequence of words from source language to target language.
Source: RNN for Machine Translation
Inputs and Outputs
Input is a sentence in source language, which is usually encoded in terms of a vector using encoding schemes like one-hot encoding, word2vec, glove. Output is a sentence in target language. Actual output from the network is the probability over all words in the vocabulary.
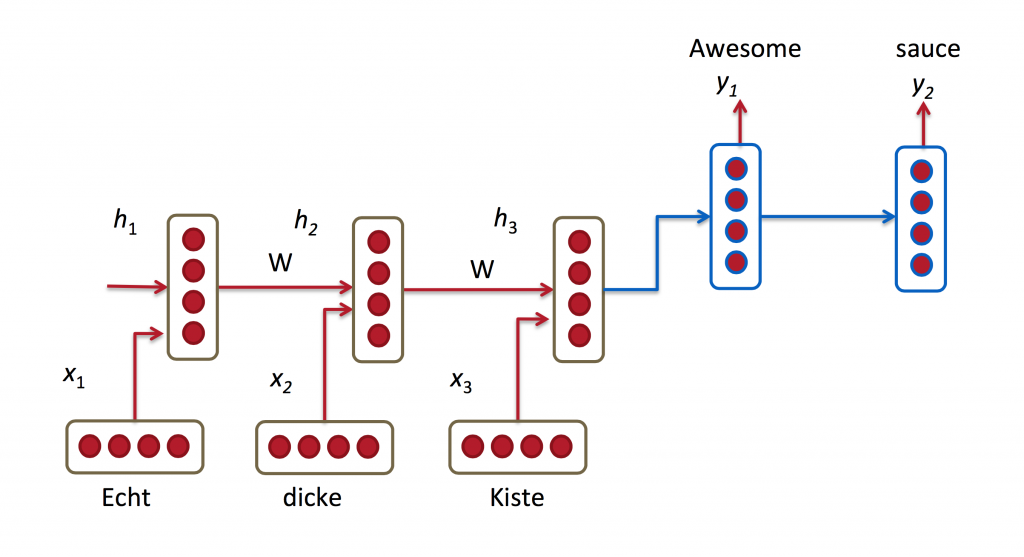
Complete model
The above diagram shows a RNN being unrolled into a full network. Think of them as a smart summary of an input sequence into a fixed-sized state vector via recursive update, where each time-step depends on previous time step and current input. RNNs are different from plain NNs in the sense that same weights/parameters are used across all time-steps. The above network represents a fully connected directed generative model, where every variable is predicted from all previous ones. Joint probability distribution is broken down into a series of conditional probabilities, requiring far less number of parameters.
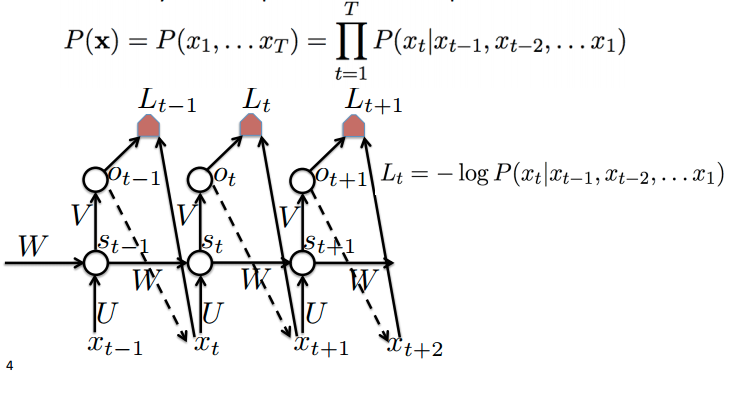
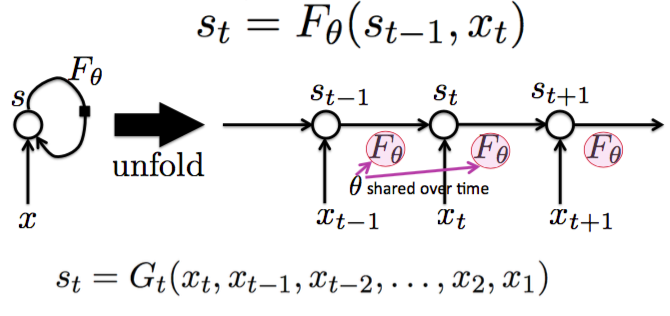
The above diagram represents generative rnns where the output of state t-1 serves as input to state t. This method generates sequence in a probabilistic sense. Since this network has only seen nice things during training, when shown something different there’s no guarentee that it produces good outputs. It may go into big bang state or not produce any output at all. It leads to compounding error from one timestep to the next. This is dealt with injecting/sampling noise during training, also called scheduled sampling (S.Bengio ‘15)
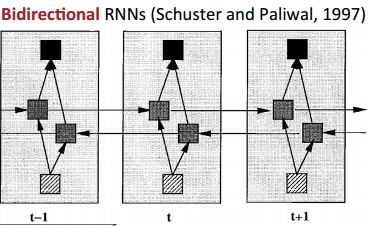
The above diagram represents Bidirectional RNNs. Vanilla RNNs have the problem of having seen data only in one direction (from left to right) which leads assymetry in time. Getting the whole context is almost always benificial, particularly in machine translation for effective information transfer.
Types of conditional distributions
- Sequence to Vector
- Sequence to Sequence of the same length, algined
- Vector to Sequence
- Sequence to Sequence of different lengths, unaligned
Why is it hard to train long sequences
Reliabily storing bits of information requires derivatives to be lesser than 1. In the loss function of RNNs, derivates from time T to 1 are multiplied. If derivatives are less than 1, it will have a compounding effect and end up converging to 0 exponentially fast. Vanishing gradient in plain NN is different from case in RNNs. In plain NN, per-layer learning rate can be rescaled, but this can’t be done in RNNs since weights are shared and total true gradient is sum over different depths, some of which will vanish, and others will dominate exponentially. The short term effects will dominate, long term effects will vanish.
Solutions to vanishing/exploding gradients
- Gradient clipping
- Shortcuts/ Delays - gradient can flow through shortcuts and reach till the first, easily capturing long-term dependencies
- Sparse gradients
- Gated self-loops (LSTM)
Hierarchical RNNs

Two or more levels are introduced in the vanilla recurrent networks, one of which handles short term dependencies and other which updates at regular intervals, handling long term dependencies.
LSTM and GRU try to mimic the behaviour of hierarchical rnns by having gating units and forget gates, effectively controlling which long-term dependencies should stay. If the forget gate is 0, no information is passed from t-1 to t. If forget gate is 1, information is copied from t-1 to t
Attention networks
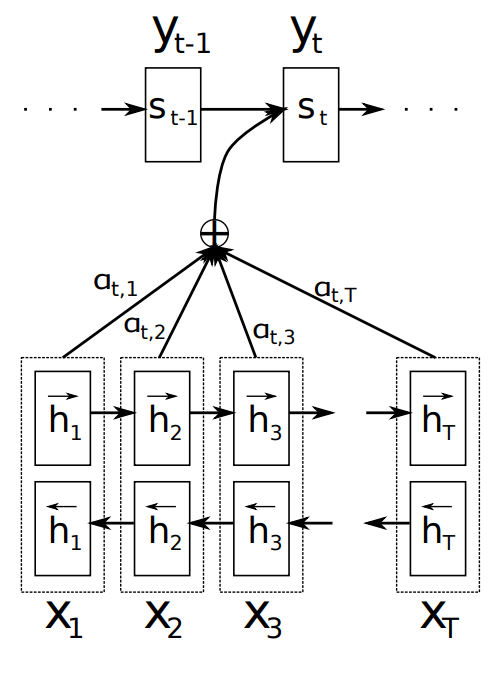
Standard seq2seq models typically try to encode the input sequence into a fixed length vector (the last hidden state) based on which the decoder generates the output sequence. However, it is unreasonable to assume the all necessary information can be encoded in this one vector. Thus, the decoder depends on an attention vector, which is based on the weighted sum (expectation) of the input hidden states. The attention weights are learned jointly, as part of the network architecture and come from a softmax-normalized attention function. Instead of saying y is generated from last hidden state, all of the hidden states of entire encoding process are available to us (pool of source states to draw from). The attention mechanism has improved accuracy, particularly on long sentences, confirming the hypothesis that fixed vector encoding is a bottleneck.
Attention is expensive, because it must be evaluated for each encoder-decoder output pair, resulting in a len(x) * len(y) matrix. The model predicts a target word based on the context vectors associated with source/input positions and all the previous generated target words. Incase of English to French translation, the attention matrix has large values on the diagonal, showing these two languages are well algined in terms of word order (ref below)

Broadly speaking, there are two types of attention mechanisms:
- Contextual attention - This element captures trend/ changepoints in data
- Temporal attention - This element captures seasonality
Case Study
There are several architectures in the field of Recurrent Networks that have a name. The most common are:
- Pointer Networks. The next word generated can either come from vocabulary or is copied from the input sequence
- Zoneout. Randomly choose skip-connections that are stochastically decided (similar to drop-out)
Open problems
Brain doesn’t do backpropagation through time (BPTT) when it learns about sequences because it hasn’t seen the whole sequence yet. It adapts and speaks out online (at the moment, given past history). Real-time recurrent learning (RTRL) uses forward evaluation of the gradient meaning as we move forward in time, derivates are computed for each state variable with respect to parameters using approximate gradient estimators. This area of machine learning is called online learning. Read more here: Training recurrent networks online without backtracking